开源软件DBT中文社区
微信号:DBT_CN
QQ群:551308350

使用 fal 和 dbt 从 Jupyter Notebooks 构建和部署机器学习模型
-
介绍
机器学习 (ML) 在数据驱动的决策中越来越重要,因此使用现代工具和技术来简化机器学习工作流程非常重要。这就是 dbt 和 fal 可以发挥作用的地方 - 它们一起使以可扩展和可重现的方式管理和部署机器学习模型变得容易。在这篇博文中,我们将引导您了解如何使用 fal 和 dbt 来训练和存储逻辑回归 ML 模型,对新数据进行预测,并将这些预测存储在 dbt 模型中。在这篇文章结束时,您将具备将这些工具应用于您自己的 ML 项目的技能和知识。设置
我们准备了一个示例项目,您可以在阅读此博客文章时使用它。它既有一个带有一些合成数据的dbt项目,也有一个示例Jupyter笔记本。您可以克隆它:git clone https://github.com/fal-ai/dbt_fal_ml_example
我们使用dbt-fal作为Python适配器。这是运行dbt Python模型的最简单方法。该项目还使用 BigQuery 作为数据仓库。您可以编辑 require.txt 文件以适合您自己的数据仓库。然后,您可以通过运行以下命令在新的 Python 环境中安装项目要求:python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
让我们在项目目录中创建一个文件,并用必要的凭据填充它:profiles.ymlexample_shop:
target: staging
outputs:
staging:
type: fal
db_profile: db
db:
type: bigquery
method: service-account-json
...
输出应包含数据仓库凭据。db最后,让我们启动 Jupyter 笔记本:
jupyter notebook notebooks/Experiments.ipynb
这将在您的终端中打印出一个 URL,您可以在浏览器中使用该 URL 并打开“Experiments.ipynb”笔记本。我们的示例数据集模拟零售环境中的客户订单和订单退货。该数据集包含每个订单的客户年龄、订单总价以及是否退回信息。
数据探索和准备
在我们的笔记本中,我们首先导入所有必要的模块:import pickle
import uuid
import pandas as pd
import matplotlib.pyplot as pltfrom sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from fal import FalDbt
Jupyter 笔记本允许我们运行 shell 命令,因此我们可以运行和:dbt seeddbt run!dbt seed --profiles-dir ..
!dbt run --select customer_orders customer_orders_labeled --profiles-dir ..
如您所见,我们正在计算两个 dbt 模型,并且 .顾名思义,一个数据集包含标记的数据,而另一个数据集包含未标记的“新鲜”数据。customer_orderscustomer_orders_labeled让我们看一下模型。我们必须实例化:customer_orders_labeledFalDbt
faldbt = FalDbt(project_dir="..", profiles_dir="..")
现在我们可以将模型下载为 pandas 数据帧并打印顶部行:customer_orders_labeledorders_df = faldbt.ref("customer_orders_labeled")
orders_df.head()
这将打印如下所示的表:order_id customer_id total_price age return0 210.0 488.0 187.861698 18.0 0.0
1 263.0 578.0 628.745330 18.0 0.0
2 360.0 578.0 99.154886 18.0 0.0
3 482.0 818.0 393.284591 18.0 0.0
4 594.0 656.0 339.542104 18.0 0.0
该列是数字,其中表示尚未返回订单,表示已返回订单。由于它是我们要预测的列的值,因此我们将此列称为标签,其他列是特征。让我们假设特征和 not 在是否返回订单方面不起作用。这给我们留下了和.return0.01.0returnorder_idcustomer_idtotal_priceage可视化要素和标注之间关系的一个好方法是绘制绘图。我们可以通过使用库轻松做到这一点:matplotlib
plot_data = orders_df.sample(frac=0.1, random_state=123)
colors = ['red' if r else 'blue' for r in plot_data['return']] # assign colors based on whether or not order was returned
plt.scatter(plot_data['age'], plot_data['total_price'], c=colors)
plt.xlabel('Age')
plt.ylabel('Total Price')
plt.show()
这是结果图:
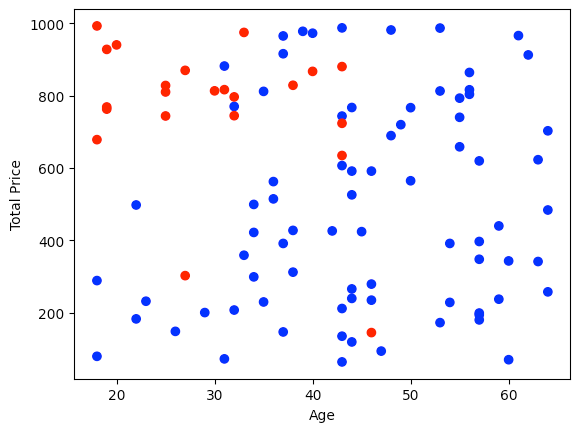
退货(红色)和未退货(蓝色)订单的年龄和价格分布
红点对应于已退货的订单。我们可以从图中看到,左上角的订单往往比其他订单更频繁地退货。
ML 模型训练和评估
我们将训练和评估的 ML 模型类型称为逻辑回归。逻辑回归适用于此问题,因为目标标签 () 是二进制的(0 或 1),逻辑回归模型可以输出介于 0 和 1 之间的概率。在我们的例子中,逻辑回归模型的输出将是给定客户的年龄和订单总价格的订单被退回的概率。return我们首先将数据集拆分为训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(
orders_df[['age', 'total_price']],
orders_df['return'],
test_size=0.2,
random_state=42)
这会将数据集拆分为训练集和测试集,其中 80% 的数据用于训练,20% 的数据用于测试。接下来,让我们在训练集上训练一个逻辑回归模型。我们将使用 来自 的类对象,它是逻辑回归的快速简单实现:LogisticRegressionscikit-learn
lr_model = LogisticRegression(random_state=42)
lr_model.fit(X_train, y_train)
对象的方法进行训练。一旦这个单元完成计算,将使用我们的数据进行训练。fitlr_modellr_model训练模型后,我们可以使用以下方法评估其在测试数据上的性能:predict
Make predictions on the test data
y_pred = lr_model.predict(X_test)
Print a classification report
print(classification_report(y_test, y_pred))
这将输出一个分类报告,其中汇总了模型的性能:precision recall f1-score support 0.0 0.87 0.97 0.91 227 1.0 0.85 0.53 0.66 73 accuracy 0.86 300macro avg 0.86 0.75 0.79 300
weighted avg 0.86 0.86 0.85 300
分类报告显示,该模型在测试数据上的准确率为 0.86。对于类 0(无返回),模型的精度为 87.0,对于类 0(返回),模型的精度为 85.1。0 类模型的召回率为 97.0,0 类的召回率为 53.1。该模型的 F1 分数在 0 类为 91.0,对于 0 类为 66.1。我们可以看到,该模型对于类 0(无返回)具有良好的精度和召回率,但对于类 1(返回)具有较低的精度和召回率。这表明该模型可能比预测将返回的订单更能预测不会返回的订单。尽管如此,该模型的总体准确度为 0.87,表明它可以对新数据做出相当准确的预测。
使用 dbt 模型自动执行 ML 训练
将模型训练工作流存储在 dbt 模型中,使我们能够对模型数据进行版本控制并与其他用户共享。我们首先在目录中创建一个新的 dbt 模型:。这是一个 Python 模型,我们将上面的笔记本代码改编到模型定义中:modelsorder_return_prediction_models.pyimport pickle
import uuid
import pandas as pd
import datetime
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_reportdef model(dbt, fal):
dbt.config(materialized="table")
orders_df = dbt.ref("customer_orders_labeled")
X = orders_df[['age', 'total_price']]
y = orders_df['return']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)print("Model init") lr_model = LogisticRegression(random_state=123) print("Model fitting") lr_model.fit(X_train, y_train) # Test model y_pred = lr_model.predict(X_test) print("Preparing the classification report") # Create a report and put it in a DataFrame model_name = str(uuid.uuid4()) y_test = y_test.astype(float) report = classification_report(y_test, y_pred, output_dict=True) report["model_name"] = model_name report["date"] = datetime.datetime.now() output_df = pd.DataFrame([report]) output_df = output_df.rename(columns={"0.0": "target_0", "1.0": "target_1"}) output_df.set_index("model_name") print("Saving the model") # Save model weights with open(f"ml_models/{model_name}.pkl", "wb") as f: pickle.dump(lr_model, f) return output_df该模型获得标记的订单数据并训练逻辑回归模型。然后评估模型,并将报表与唯一的模型名称一起存储在数据帧中。接下来,我们将模型权重保存到本地存储。您可以修改此步骤以将模型权重存储在云存储平台(例如 S3)上。最后,返回输出数据帧,因此其内容将保留在我们的数据仓库中。order_return_prediction_modelslr_model
我们可以运行这个 dbt 模型:
dbt run --select order_return_prediction_models
使用存储的模型进行预测
首先,我们尝试在Jupyter笔记本中进行预测,然后我们创建一个Python模型来自动执行此操作。在我们的 Jupyter 笔记本中,我们可以轻松找到最准确的模型:
models_df = faldbt.ref("order_return_prediction_models")
best_model_name = models_df[
model_df.accuracy == models_df.accurary.max()
].model_name[0]
然后,我们从本地存储(或云存储提供商)加载此模型:with open(f"../ml_models/{model_name}.pkl", "rb") as f:
loaded_model = pickle.load(f)
我们还加载新订单数据并检查其外观:orders_new_df = faldbt.ref("customer_orders")
orders_new_df.head()
这将打印出一个表格:order_id customer_id total_price age0 1037.0 981.0 193.460803 19.0
1 1027.0 940.0 680.986976 21.0
2 1039.0 123.0 952.906524 22.0
3 1043.0 860.0 545.791012 22.0
4 1046.0 316.0 887.003551 24.0
如我们所见,此数据帧的形状与 不同 缺少列。这是我们想要预测的列。customer_orders_labeledreturn所以,让我们做一个预测:
predictions = loaded_model.predict(orders_new_df[["age", "total_price"]])
orders_new_df["predicted_return"] = predictions
order_new_df.head()
在上面的代码片段中,我们首先执行预测,然后将生成的预测附加到数据帧。这是 of 应该的样子:orders_new_dfheadorders_new_dforder_id customer_id total_price age predicted_return0 1037.0 981.0 193.460803 19.0 0.0
1 1027.0 940.0 680.986976 21.0 1.0
2 1039.0 123.0 952.906524 22.0 1.0
3 1043.0 860.0 545.791012 22.0 1.0
4 1046.0 316.0 887.003551 24.0 1.0
让我们绘制我们的预测,看看它们是否有意义:plot_data = orders_new_df.sample(frac=0.5, random_state=123)
colors = ['red' if r else 'blue' for r in plot_data['predicted_return']]
plt.scatter(plot_data['age'], plot_data['total_price'], c=colors)
plt.xlabel('Age')
plt.ylabel('Total Price')
plt.show()
这是结果图:
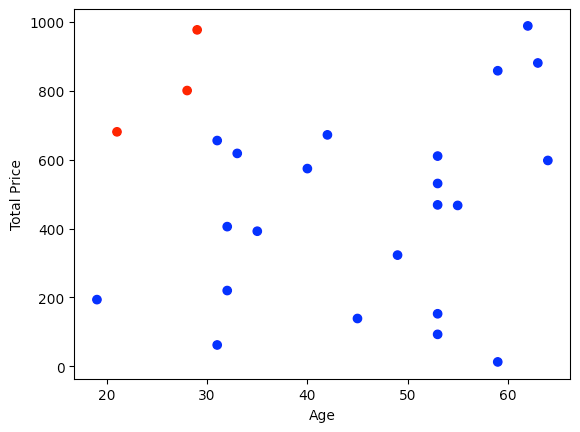
如果这些值对我们来说看起来不错,我们可以创建另一个 dbt Python 模型来自动运行这些预测。这个新的dbt模型将首先选择最佳的逻辑回归模型,使用它来预测订单是否会被退回,最后将其预测存储在我们的数据仓库中。predicted_return以下是我们新模型的定义:order_return_predictions.py
import pickle
def model(dbt, fal):
dbt.config(materialized="table")
models_df = dbt.ref("order_return_prediction_models")
best_model_name = models_df[
models_df.accuracy == models_df.accuracy.max()].model_name[0]
with open(f"ml_models/{best_model_name}.pkl", "rb") as f:
loaded_model = pickle.load(f)
orders_new_df = dbt.ref("customer_orders")
predictions = loaded_model.predict(orders_new_df[["age", "total_price"]])
orders_new_df["predicted_return"] = predictions
return orders_new_df
我们可以运行这个 dbt 模型:dbt run --select order_return_predictions
结论
在这篇博文中,我们介绍了如何使用 fal 和 dbt 以可扩展和可重现的方式管理和部署机器学习模型。我们使用合成购物数据集来训练一个逻辑回归模型,该模型可以预测订单被退回的概率。我们在 dbt 模型中自动化了 ML 训练过程,并使用生成的 ML 模型对新数据进行预测。最后,我们能够将结果预测存储在新的dbt模型中。所有这些现在都可以自动运行。